Fortran是人类最古老的的一门高级语言,而它的优点就在于能进行大规模的科学计算。Fortran对许多基础的数学计算都有非常多大的加速(比如对一个数组通式求正弦),因而很多科学计算程序都是用Fortran实现。而并行计算无疑能在此基础之上给Fortran一个更大的提速。本文主要讲解如何使用Fortran实现并行计算。
编译器的选择
一般来说,Fortran的编译器都是选择Intel的 Visual Fortran和VS结合实现(如果是用的Intel的CPU的话,这个加速相当完美,这是其他编译器无法超越的)。然而,由于我是要拿他来和Python做混编,Intel的编译器老是有问题。无奈之下,采用GNU的GFortran编译器。
IDE配置
目前GFortran最流行的编译器是Code::Blocks(这不是以前搞竞赛的时候用的么。。)点开设置-编译器如下图:
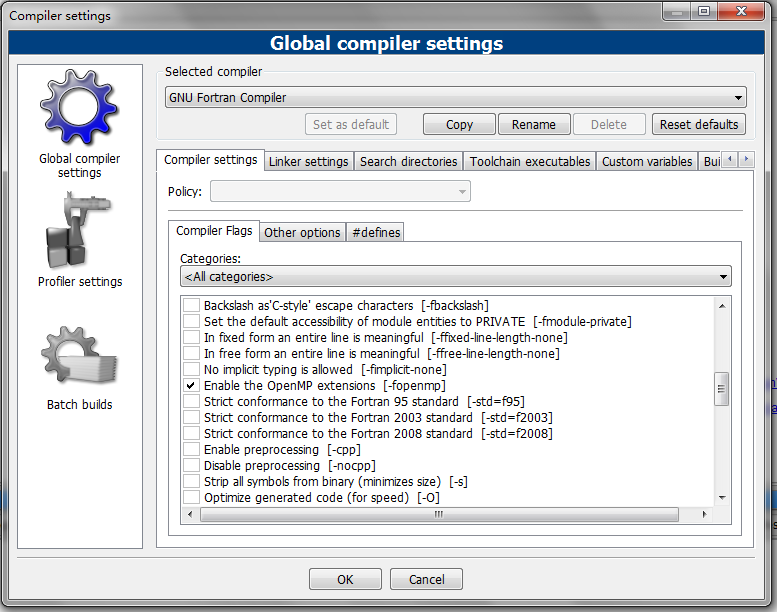
设置编译器为GNU Fortran Compiler
在Compiler Flags下面勾选上 Enable the openMP extension[-fopenmp]
在Linker settings里面添加链接库 C:\MinGW32-xy\bin\libgomp-1.dll(根据自己minGW安装位置而定)
在Other linker options选项中添加 -lgomp -lpthread两项
到此编译器的环境就配置完成了
程序编写
openMP通过注释的方式在fortran语句中实现并行。在!$OMP PARALLEL和!$OMP END PARALLEL之间的语句表示这里面是并行的程序块,而!$OMP DO和!$OMP END DO块表示这是一个do循环,而且这个循环需要用并行方式处理。除此之外还有其他若干种并行方式,需要的时候很容易在网上找到。
下面我们来编写一个例子:
1 | ! A fortran95 program for G95 |
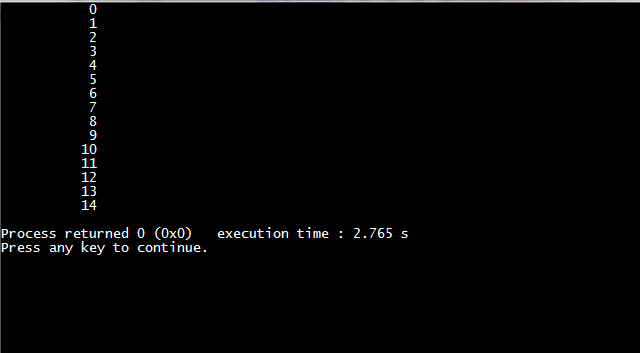
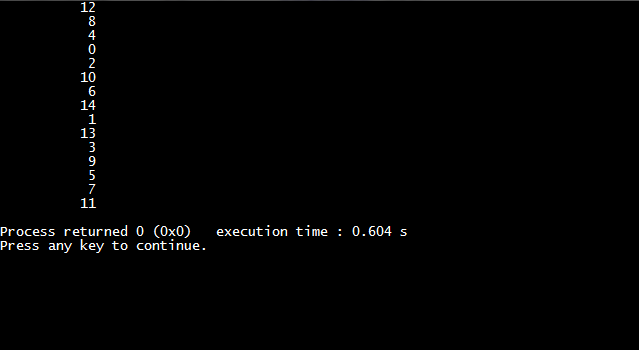
以下是运行结果:
串行:
并行:
注意事项
-
GFortran有一个规定就是一行最多72个字符(可能是古代穿孔机只能穿那么大的纸,这个习俗保留到了现在)。因此超过72个字符编译器就不认了,如果出了莫名其妙的错误,就说明有可能超限制了。这个时候需手动换行,选一处加上&然后回车,再在下一行加上&
-
并行计算的时候do循环间坚决杜绝线程间有交叉使用的变量。否则出现竞争的情况,结果是并行速度比串行慢的,且程序有可能每次算得的值都不一样。比如下面这个程序,并行一定比串行慢,因为重复使用了变量j。
1 | !$OMP PARALLEL |