By Z.H. Fu
https://fuzihaofzh.github.io/blog/
SVM (Support Vector Machine) is an important tool in pattern recognition before the wave of different kind of neural networks. In this post, we revisit the derivation of SVM and get some important intuition of the result.
The original problem
Suppose we have some training data D={(x1,y1),(x2,y2),⋯,(xn,yn)}, in which x is a feature vector, and yi is the class label for each sample and it is -1 or 1. Our task is to find a classifier that uses a separate hyper plane to divide the points in D into two parts. Points on each side of the hyper plane have the same class label y respectively. This classifier is denoted as f(x)=sign(wTx+b). For any hyper plane that successfully divide the two classes. We define the geometry margin of the ith point as the distance from the point to the hyper plane:
γi=∣∣w∣∣yi(wTxi+b)
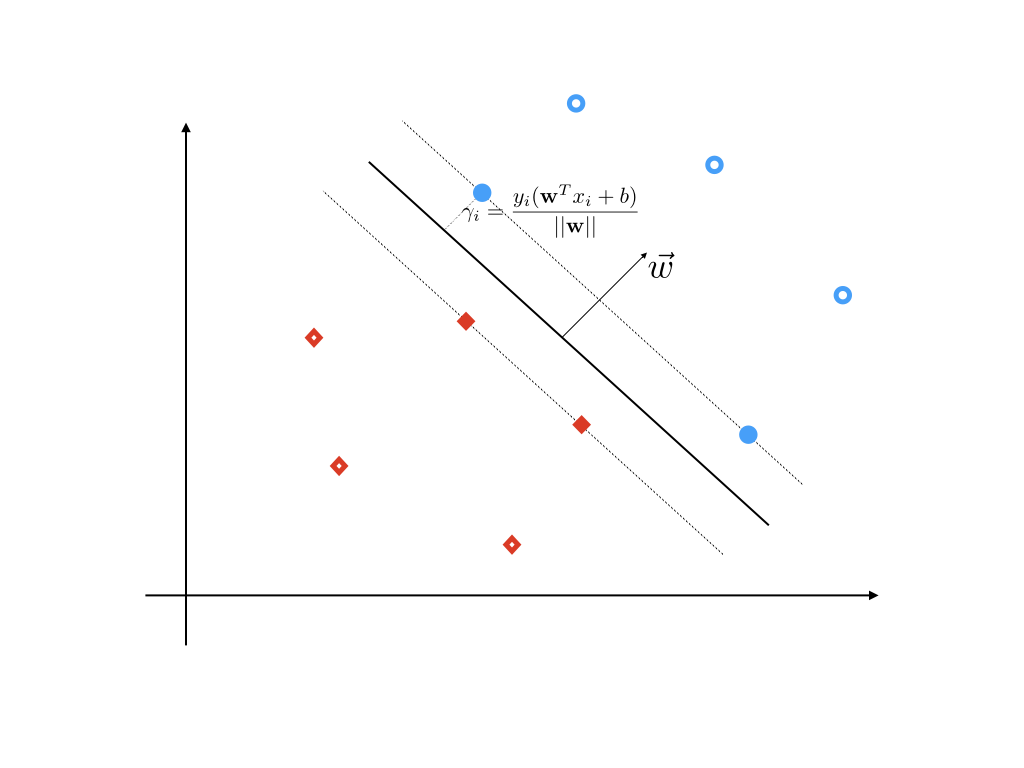
We observe that for both classes y=1 and y=−1, the geometry margin is larger than 0. We can define the geometry margin of our dataset D as:
γ=i=1,⋯,nminγi
We can see that there are a lot of possible hyper planes. Our ultimate goal is to find the best hyper plane (with parameter (w∗,b∗)) that maximize the geometry margin of the dataset D. Only the geometry margin of the dataset is maximized, can some points between two classes been classified correctly. We can write our problem in the standard optimization form as:
(P) s.t. w,bmaxγ∣∣w∣∣yi(wTxi+b)≥γ,i∈[1,n]
To make our problem easy to solve, we can convert it into its dual form. First of all, we define the function margin to help our further derivations. A function margin of ith point is defined as:
γi^=yi(wTx+b)
The function margin of the whole dataset is defined as:
γ^=i=1,⋯,nminγ^i
It can be easily observed that γ=∣∣w∣∣γ^.
The original problem can be rewritten as:
s.t. w,bmax∣∣w∣∣γ^yi(wTxi+b)≥γ^,i∈[1,n]
We observed that γ^ can be assigned to any value, because if we change γ^ to λγ^, we can adjust (w, b) to (λw, λb) to make the problem unchanged. As a result, we can assign γ^=1 to simplify the problem, i.e.
s.t. w,bmax∣∣w∣∣1yi(wTxi+b)≥1,i∈[1,n]
To maximize $ \frac{1}{||\mathbf{w}||}$ is the same as minimize ∣∣w∣∣, and the problem changes to:
s.t. w,bmin21∣∣w∣∣2yi(wTxi+b)≥1,i∈[1,n]
Next, we want to merge the constrains into the objective function to make it an unconstrained problem. We want to design a function gi(w,b), s.t.
gi(w,b)={0∞ if (w,b) fulfill the ith constrain otherwise
It can be written into a more compact form with the max notation:
gi(w,b)=αi≥0maxαi[1−yi(wTx+b)]
In which, αi is called the Largrange multiplier. If (w,b) fulfill the constrain, 1−yi(wTx+b)≤0 and αi=0 to attain its max value 0. On the other hand, if (w,b) violate the constraint, 1−yi(wTx+b)>0 and αi=∞ to attain its max value ∞.
Thus, the optimization problem can be written as $$\begin{aligned}&\min_{\mathbf{w},b}\frac{1}{2}||\mathbf{w}||2+\sum_{i=1}ng_i(\mathbf{w},b)\
=&\min_{\mathbf{w},b}\frac{1}{2}||\mathbf{w}||2+\sum_{i=1}n\max_{\alpha_i\ge0}\alpha_i[1-y_i(\mathbf{w}^T\mathbf{x}+b)]\
=&\max_{\alpha_i\ge0}\min_{\mathbf{w},b}\frac{1}{2}||\mathbf{w}||2+\sum_{i=1}n\alpha_i[1-y_i(\mathbf{w}^T\mathbf{x}+b)]\
=&\max_{\alpha_i\ge0}\min_{\mathbf{w},b}J(\mathbf{w},b,\mathbf{\alpha})
\end{aligned}$$
In which J(w,b,α)=21∣∣w∣∣2+∑i=1nαi[1−yi(wTx+b)]. The inside minimize problem can be solved by setting the derivative to 0:
∂w∂J(w,b,α)∂b∂J(w,b,α)=w−i=1∑nαiyixi=0=−i=1∑nαiyi=0
We get w∗=∑i=1nαiyixi, substitute it into the optimization problem we get:
αi≥0maxi=1∑nαi−21i=1∑nj=1∑nyiyjαiαjxiTxj
We write it into a formal optimization problem:
(D) αmin s.t. 21i=1∑nj=1∑nyiyjαiαjxiTxj−i=1∑nαii=1∑nαiyi=0αi≥0,i∈[1,n]
This is the dual optimization problem of problem (P) and it is a standard Quadratic Programming which can be solved by a lot of solvers.
Some obervations and intuitions
-
The variable of the primal optimization problem (P) is to optimize (w,b) while the dual problem (D) is to optimize the dual variable α. The length of dual variable equals to the number of constrains of the primal problem.
-
If αi=0, yi(wTxi+b)>1 the function margin of this is not equal to the function margin of the dataset (γ^=1) . It means that the margin of this sample is not the smallest among others.
If αi>0, it means that the ith constrain is active and yi(wTxi+b)=1. The function margin of the ith sample equals to the function margin of the dataset. This sample is called a support vector.
-
We observe the optimal value of w∗:
w∗=i=1∑nαiyix
In which αi=0 for all non support vectors, which means that the value of w∗ is only determined by support vectors.
Reference
[1] 李航. 统计学习方法.
[2] Xiaogang, Wang. “ENGG5202 Lecture notes.” Chapter8.