Elasticsearch is a powerful search engine based on Lucene. It can build indexes on huge amount of data and we can query the data fast by keywords. Different from common database, Elasticsearch build inverted index and is capable of search keywords on all documents. The serch tool of wikipedia now is Elasticsearch. In this post, we introduce how to make a local Elasticsearch and import wikipedia dump into it. Some basic usages of Elasticsearch are also introduced.
Download Elasticsearch
We run Elasticsearch on Linux system. Fisrly, we download Elasticsearch from the web.
We installed some plugins provided by wikimedia. Afterwards, we start Elasticsearch by:
1
./bin/elasticsearch
Do not follow the official old post
This famous post provided by Elasticsearch https://www.elastic.co/blog/loading-wikipedia is out-of-date since recently, a lot of changes have been made in the development of Elasticsearch. I personally encountered a lot of problems during reproduce this tutorial. And I cannot find the solution.
Use Logstash
Logstash is log processing tool. However, it can also be used as the processing tool of our data. Since wikipedia dump is a text stream, Logstash can process text data by a rich set of plugins.
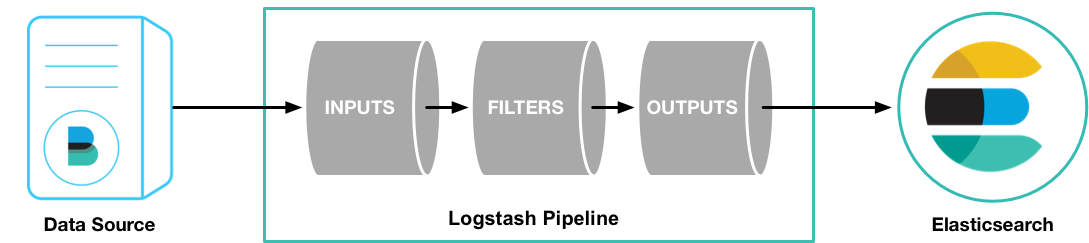
The framework of Logstash is shown as follows
We can define our own Imput, Filter and Output part to process the text stream to our desired data.
Firstly, we download Logstash and unzip it.
1 2 3
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.1.1.zip unzip logstash-6.1.1.zip cd logstash-6.1.1
Then, we make our config file to define the three parts of Logstash. The config file wikipedia.conf is as follows:
In the input part, we get text stream from stdin. We use multiline codec to seperate the text by xml tag <page>. In the filter part, we use two filters. The first is xml filter, it use xpath to extract information we need and pass the information to the next filter mutate. Mutate is a filter used to modify the data. Here, we removed some fields and convert the title and id from array to string. Afterwards, we use gsub module to do some regexp replacement to preprocess the raw text. Finally, we defined the output part. We set the output node to Elasticsearch (Logstash also support a lot of output database). we set the index of our data and we set the id of each document the same with our extracted id.
Here, bunzip2 -c output the file to stdout, by the pipline, the text stream is sent to logstash.
Use stream2es
stream2es(https://github.com/elastic/stream2es) is an old tool provided by Elasticsearch team. If you think Logstash takes too much time, you can consider using this tool instead. Stream2es can import different kinds of formats of data into Elasticsearch. Please be noted that there are some size limit of jave. So we have to change the limit in the importing command. The command is as follows:
During the importing, Stream2es will stuck and cannot import more data.
Some basic operation of Elasticsearch
View Index Information
After importing the data, we can view the index information by
1 2 3
curl -X GET 'http://localhost:9200/_cat/indices?v' health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open enwiki InluFbzVRB24smaRgr2h2A 5 1 17959833 327 57gb 57gb
We can see that we have 17959833 documents and it occupy 57Gb disk.
Search by content
We use the following command to search the keyword “”
{ "took":5, "timed_out":false, "_shards":{ "total":5, "successful":5, "failed":0 }, "hits":{ "total":149, "max_score":22.093157, "hits":[ { "_index":"enwiki", "_type":"doc", "_id":"6713515", "_score":22.093157, "_source":{ "@version":"1", "@timestamp":"2018-01-01T12:44:47.083Z", "text":[ "<text xml:space=\"preserve\">{{Infobox venue\n| name= Beihang University Gymnasium\n|image=[[Image:2008 BUAA Gymnasium Indoor Arena.JPG|250px]]<br>The indoor arena at the 2008 Summer Olympics.\n|location=[[Beihang University]]\n|opened=2001\n|owner=Beihang University\n|seating_capacity=5,400\n|tenants=Beihang University }}\n'''Beihang University Gymnasium''' ({{Zh|s=北京航空航天大学体育馆|t=北京航空航天大學體育館|p=Běijīng Hángkōng Hángtiān Dàxué Tǐyùguǎn}}, sometime listed as the '''Beijing University of Aeronautics & Astronautics Gymnasium''') is a 5,400-seat indoor arena located on the campus of [[Beihang University]] in [[Beijing]], [[China]]. It hosted [[Weightlifting at the 2008 Summer Olympics|weightlifting]] competitions at the [[2008 Summer Olympics]] and [[Powerlifting at the 2008 Summer Paralympics|powerlifting]] competitions at the [[2008 Summer Paralympics]].\n\n==References==\n*[https://web.archive.org/web/20080810035639/http://en.beijing2008.cn/venues/aag/index.shtml Beijing2008.cn profile]\n\n{{2008 Summer Olympics venues}}\n{{Olympic venues weightlifting}}\n\n{{Coord|39|58|45|N|116|20|35|E|type:landmark|display=title}}\n\n[[Category:2008 Summer Olympic venues]]\n[[Category:Sports ve\nnues in Beijing]]\n[[Category:Indoor arenas in China]]\n[[Category:Olympic weightlifting venues]]\n\n\n{{PRChina-sports-venue-stub}}\n{{2008-Olympic-stub}}</text>" ], "title":"Beihang University Gymnasium", "id":"6713515" } }, { "_index":"enwiki", "_type":"doc", "id":"19983118" } }, { "_index":"enwiki", "_type":"doc", "_id":"55716559", "_score":19.37609, "_source":{ "@version":"1", "@timestamp":"2018-01-01T13:56:25.637Z", "text":[ "<text xml:space=\"preserve\">#redirect [[Beihang University]]</text>" ], "title":"Beijing Univ. of Aeronautics and Astronautics", "id":"55716559" } } ] } }