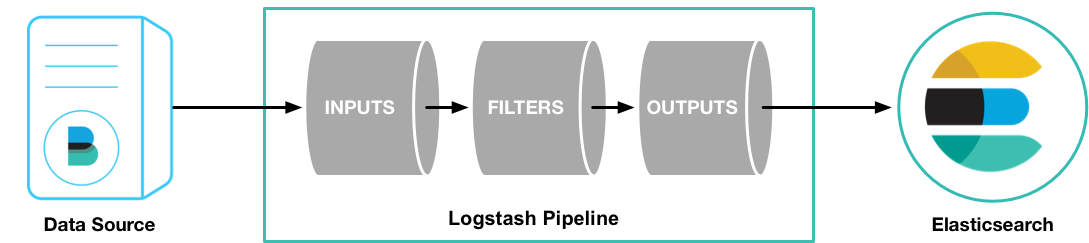
By Z.H. Fu
https://fuzihaofzh.github.io/blog/
Optimization is the foundation of many other popular technologies and is widely used in our modern society. In this post, we will go through the basics in the foundation of optimization. We will start from the simplest linear programming, extend it to a more general conic version and finally arrive at Lagrange optimization. In order to concentrate on the main framework of optimization, we leave out some long proof which can be easily found in reference materials. All this post comes from course ENGG5501 taught by Prof. Anthony Man-Cho So in CUHK.
(I) Linear Programming
In linear programming (LP), the objective function and constraints are all linear w.r.t. variables. The standard form of linear programming is given as follows:
(P) vp∗=xmin s.t. cTxAx=bx≥0
Where x,c∈Rn, b∈Rm A∈Rm×n. Since x≥0, the feasible region contains no line. It implies that it has at least one vertex. As stated by a theorem, if (P) has at least one vertex. Then, either the optimal value is −∞ or there exists a vertex that is optimal.
Weak Duality
By observing problem (P). We are minimizing some function. A natural question is whether we can construct a lower bound, such that, no matter how we change our variables, the object functions always bigger than the lower bound. Now, let construct such a lower bound.
If we can find a vector y∈Rm, s.t. ATy≤c, then we have bTy=xTATy≤cTx. This is in fact another optimization problem. Because, for all ys, the inequality above all holds. Obviously we want to find the max one to get the maximal lower bound. We firstly write the problem as follows:
(D) vd∗=xmax s.t. bTyATy≤c
Here, we find that for any LP primal problem (P), there exists a dual problem (D). The optimal value of the dual problem (D) is a lower bound of the primal problem (P). This is called the weak duality. By “weak”, we mean that we have an inequality relation holds between the two problems ( $ v _ p ^ * = v _ d ^ * $ ). A natural question is when the primal optimal value equals to the dual optimal value ($v _ p^ * = v _ d^ * $). It will be powerful if the equality holds, because if $v _ p^* = v _ d^* $, we can solve the primal problem by just solving the dual problem if the primal problem is to complicated. When the equality will hold is studied in the strong duality theory.
Strong Duality
To get the strong duality, we first introduce Farkas’s Lemma without proof.
(Farkas’s Lemma) Let A∈Rm×n and b∈Rm be given. Then, exactly one of the following systems has a solution:
Ax=b,x≥0ATy≤0,bTy>0
Farkas’s Lemma shows that there must be one and only on of the two systems has a solution. This can be used to prove the strong duality of LP problem.
(LP Strong Duality) Suppose that (P) has an optimal solution x∗∈Rn. Then, (D) also has an optimal solution y∗∈Rm, and cTx∗=bTy∗.