By Z.H. Fu
https://fuzihaofzh.github.io/blog/
因为需要用FFD(Free Form Deformation)故而今天又学习了一下Bernstein多项式。现在将笔记记录如下。
首先给出Bernstein多项式:
$$b_{\nu,n}(x)=\binom{n}{\nu}x\nu(1-x){n-\nu},\nu=0,…,n.$$
其中x∈[a,b],(νn)是二项式系数。
我们再来回顾一下Bernstein多项式产生的历史。Bernstein多项式曾经被用来证明威尔斯特拉斯逼近定理(Weierstrass approximation theorem)。这个定理的大概意思是说:在[a,b]区间上所有的连续函数都可以用多项式来逼近。而且收敛性很强,是一致收敛。也就是说,可以将函数写成若干个Bernstein多项式相加的形式,而且,随着n→∞,该多项式将一致收敛到原函数!用表达式表示如下:
$$B_n(f)(x)=\sum^n_{\nu=0}f(\frac{\nu}{n})b_{\nu,n}(x)$$
其中x∈[0,1],当n→∞时,该多项式收敛到原函数:
$$\lim_{n\rightarrow \infty}B_n(f)(x)=f(x)$$
好,我们发现这个跟傅里叶展开一模一样,所不同的是这里用的是多项式函数,Bernstein多项式在这里充当着基函数的角色。我们自然想到,能不能舍掉一些“高频分量”得到函数的大概形状?答案是显然的。我们选取若干个点,用这几个函数值来构造Bernstein多项式,得出的多项式就是一种“滤波”后的函数。
以下引出Bézier曲线。我们现在单纯地从基于分量的关系来看,我们有:
$$B_n(x)=\sum^n_{\nu=0}\beta_\nu b_{\nu,n}(x)$$
其中βν是基函数的系数。将βν取成一些点,我们有:
$$\mathbf{B_n(x)}=\sum^n_{\nu=0}\mathbf{P_\nu} b_{\nu,n}(x),x\in[0,1]$$
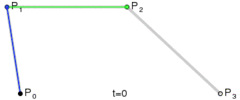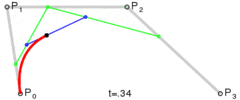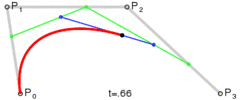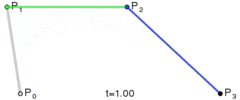
Pν是我们给的点的坐标,而当x从0到1扫过时,我们就得到了一条曲线,这就是Bézier曲线。一个直观的图形如下:
参考文献:
Bernstein polynomial
https://en.wikipedia.org/wiki/Bernstein_polynomial
Bézier curve
https://en.wikipedia.org/wiki/Bézier_curve